INTRODUCTION
In this project, the student group will program and utilize the most start-of-the-art supercomputers at the Ohio Supercomputer Center. These fast supercomputers are called Cluster Computers and unlike traditional workstations or PCs consist of hundreds of separate processors all under the user's control. Since the processors can work in parallel, clusters are capable of performing large, complex and detailed scientific and engineerings problems at a very high speed, as the student's will measure for themselves. The OSC clusters are the premiere computing machines used by the best scientific researchers in the state of Ohio.
In Massively Parallel Processing (MPP) systems (like our clusters) the processors must be connected together in some manner so that they can transfer data amongst themselves. An illustration of one type of "interconnection topology", as it is called, is shown in the image below in which each red box represents a processor in use.
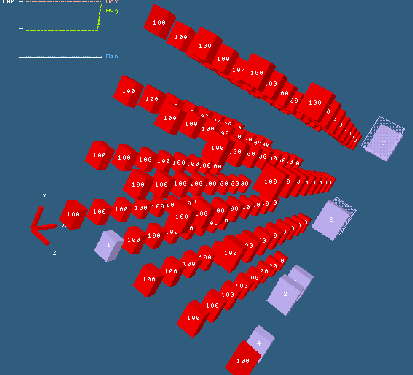
THE PROJECT
When programming for an MPP system the students will call library subroutines to send needed data from one processor to another as well as routines for the destination process to receive it. This data transmission is called message passing. Other subroutines will cause the processors to synchronize their parallel execution by setting up a red light at a certain point in the program. When all the processors have arrived at this barrier -the red light- it will turn green and processors will continue on in the code.
During the first week of the SI program the students in this project will be taught the details of MPI, the official standard of MPP message-passing libraries. MPI is an acronym for Message Passing Interface. It is large library containing hundreds of routines allowing myriad capabilities for the programmer. We will cover only the core routines of MPI routines due to time and usefulness constraints. IT IS REQUIRED THAT THE STUDENTS WHO CHOOSE THIS PROJECT ALREADY HAVE SOME EXPERIENCE PROGRAMMING IN C OR C++.
The actual scientific project that will be programmed and ran in parallel on the cluster will be decided by the student's ideas and input from the project advisor. The possibilities are unlimited. In the video you will see during the SI program, an astronomical application was used. Actual data taken with an astronomical telescope and a digital camera of the galaxy NGC 5371 was inputed to the cluster and its negative was to be calculated. The image of the left is the "positive" image of NGC 5371. The inversion of the image was done in parallel by several processors each taking a part of the image and working just on that part. The image on the right shows 8 processors working on octants of the galaxy image. In this image, each processor has partially finished the negation of its "sub-image"
 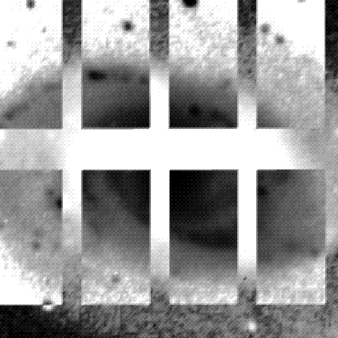 |
In parallel processing terminology, this technique is called domain decomposition.
Parallel programming through domain decomposition has been used with a number of the other scientific projects including the 1-D, 2-D, and 3-D wave motion.
ANIMATIONS
SI2006
- Team 1
- Team 2
SI2005
- Team 1
- Team 2
SI2004
SI2003
SI2002
SI2001
SI2000
SI1998
Dave Ennis is the group leader for the Parallel Processing project. His office is in OSC, cubicle 420-4, phone 292-2207.
For assistance, write si-contact@osc.edu or call 614-292-0890.