Decommissioned Supercomputers
OSC has operated a number of supercomputer systems over the years. Here is a list of previous machines and their specifications.
Ruby
Ruby was named after the Ohio native actress Ruby Dee. An HP built, Intel® Xeon® processor-based supercomputer, Ruby provided almost the same amount of total computing power (~125 TF, used to be ~144 TF with Intel® Xeon® Phi coprocessors) as our former flagship system Oakley on less than half the number of nodes (240 nodes). Ruby had has 20 nodes are outfitted with NVIDIA® Tesla K40 accelerators (Ruby used to feature two distinct sets of hardware accelerators; 20 nodes were outfitted with NVIDIA® Tesla K40 and another 20 nodes feature Intel® Xeon® Phi coprocessors).
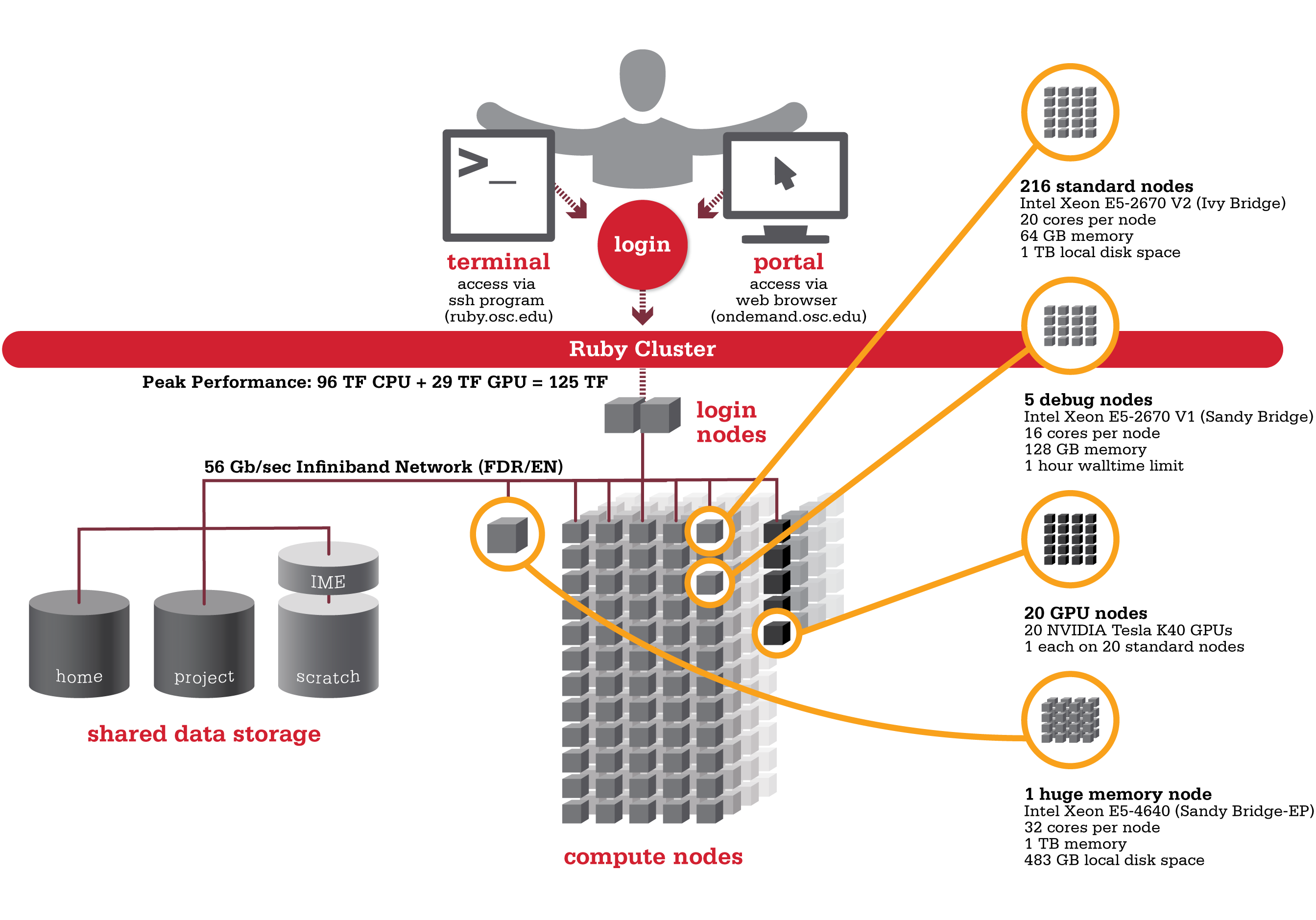
![]() Hardware
Hardware
Detailed system specifications:
- 4800 total cores
- 20 cores/node & 64 gigabytes of memory/node
- Intel Xeon E5 2670 V2 (Ivy Bridge) CPUs
- HP SL250 Nodes
20 Intel Xeon Phi 5110p coprocessors(remove from service on 10/13/2016)- 20 NVIDIA Tesla K40 GPUs
- 2 NVIDIA Tesla K80 GPUs
- Both equipped on single "debug" queue node
- 850 GB of local disk space in '/tmp'
- FDR IB Interconnect
- Low latency
- High throughput
- High quality-of-service.
- Theoretical system peak performance
- 96 teraflops
- NVIDIA GPU performance
- 28.6 additional teraflops
Intel Xeon Phi performance20 additional teraflops
- Total peak performance
- ~125 teraflops
Ruby has one huge memory node.
- 32 cores (Intel Xeon E5 4640 CPUs)
- 1 TB of memory
- 483 GB of local disk space in '/tmp'
Ruby is configured with two login nodes.
- Intel Xeon E5-2670 (Sandy Bridge) CPUs
- 16 cores/node & 128 gigabytes of memory/node
How to Connect
-
SSH Method
To login to Ruby at OSC, ssh to the following hostname:
ruby.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@ruby.osc.edu
You may see warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprint listed here, then type yes.
From there, you are connected to Ruby login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Ruby at OSC with our OnDemand tool. The first is step is to login to OnDemand. Then once logged in you can access Ruby by clicking on "Clusters", and then selecting ">_Ruby Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
File Systems
Ruby accesses the same OSC mass storage environment as our other clusters. Therefore, users have the same home directory as on the Oakley Cluster. Full details of the storage environment are available in our storage environment guide.
Software Environment
The module system on Ruby is the same as on the Oakley system. Use module load <package> to add a software package to your environment. Use module list to see what modules are currently loaded and module avail to see the module that are available to load. To search for modules that may not be visible due to dependencies or conflicts, use module spider . By default, you will have the batch scheduling software modules, the Intel compiler and an appropriate version of mvapich2 loaded.
You can keep up to on the software packages that have been made available on Ruby by viewing the Software by System page and selecting the Ruby system.
Understanding the Xeon Phi
Guidance on what the Phis are, how they can be utilized, and other general information can be found on our Ruby Phi FAQ.
Compiling for the Xeon Phis
For information on compiling for and running software on our Phi coprocessors, see our Phi Compiling Guide.
Batch Specifics
qsub to provide more information to clients about the job they just submitted, including both informational (NOTE) and ERROR messages. To better understand these messages, please visit the messages from qsub page.Refer to the documentation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- Compute nodes on Ruby have 20 cores/processors per node (ppn).
- If you need more than 64 GB of RAM per node you may run on Ruby's huge memory node ("hugemem"). This node has four Intel Xeon E5-4640 CPUs (8 cores/CPU) for a total of 32 cores. The node also has 1TB of RAM. You can schedule this node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=32. This node is only for serial jobs, and can only have one job running on it at a time, so you must request the entire node to be scheduled on it. In addition, there is a walltime limit of 48 hours for jobs on this node. - 20 nodes on Ruby are equipped with a single NVIDIA Tesla K40 GPUs. These nodes can be requested by adding
gpus=1to your nodes request, like so:#PBS -l nodes=1:ppn=20:gpus=1.- By default a GPU is set to the Exclusive Process and Thread compute mode at the beginning of each job. To request the GPU be set to Default compute mode, add
defaultto your nodes request, like so:#PBS -l nodes=1:ppn=20:gpus=1:default.
- By default a GPU is set to the Exclusive Process and Thread compute mode at the beginning of each job. To request the GPU be set to Default compute mode, add
- Ruby has 4 debug nodes (2 non-GPU nodes, as well as 2 GPU nodes, with 2 GPUs per node), which are specifically configured for short (< 1 hour) debugging type work. These nodes have a walltime limit of 1 hour. These nodes are equipped with E5-2670 V1 CPUs with 16 cores per a node.
- To schedule a non-GPU debug node:
#PBS -l nodes=1:ppn=16 -q debug
- To schedule a GPU debug node:
#PBS -l nodes=1:ppn=16:gpus=2 -q debug
- To schedule a non-GPU debug node:
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Oakley
Oakley is an HP-built, Intel® Xeon® processor-based supercomputer, featuring more cores (8,328) on half as many nodes (694) as the center’s former flagship system, the IBM Opteron 1350 Glenn Cluster. The Oakley Cluster can achieve 88 teraflops, tech-speak for performing 88 trillion floating point operations per second, or, with acceleration from 128 NVIDIA® Tesla graphic processing units (GPUs), a total peak performance of just over 154 teraflops.
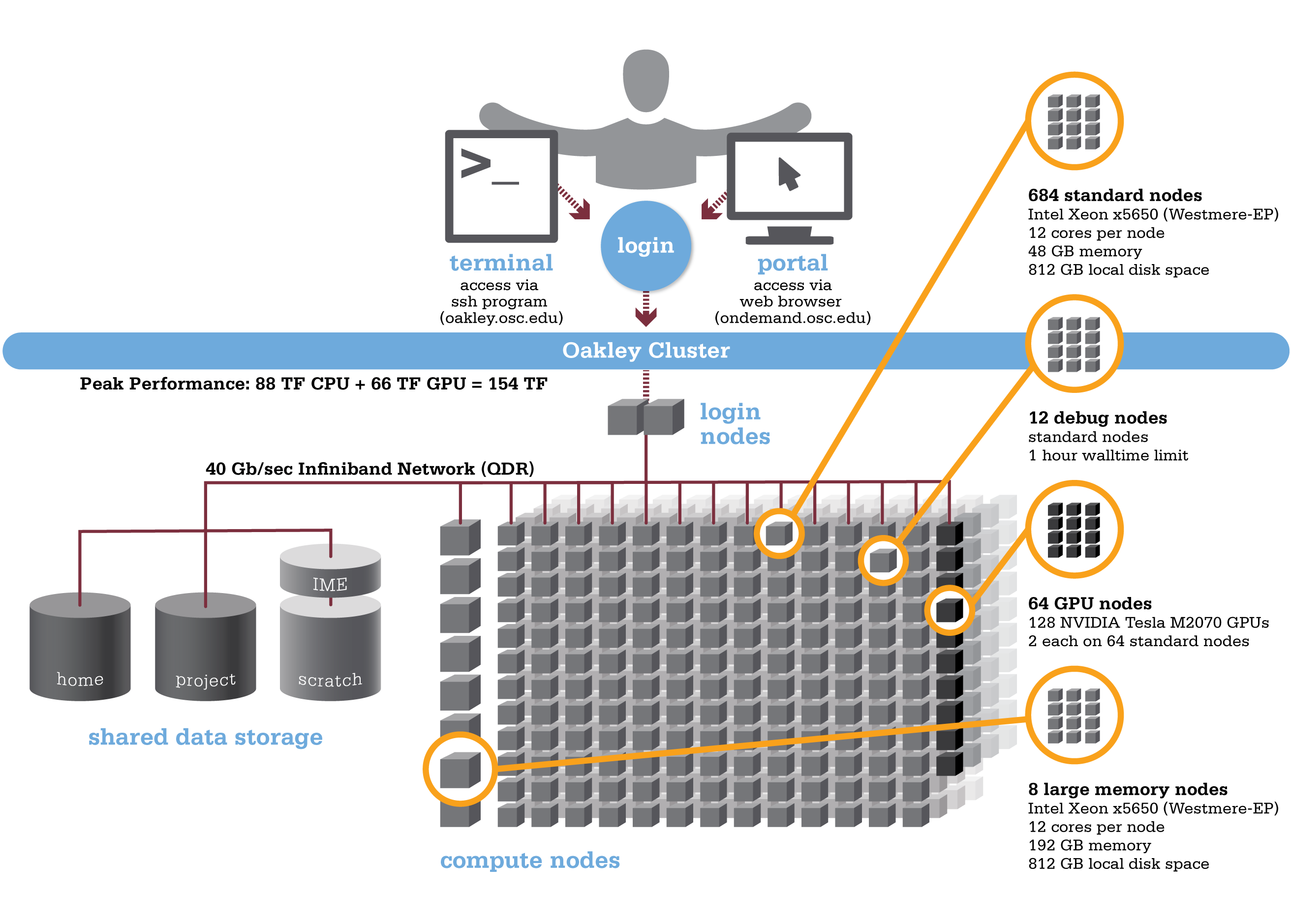
Hardware
 Detailed system specifications:
Detailed system specifications:
- 8,328 total cores
- Compute Node:
- HP SL390 G7 two-socket servers with Intel Xeon x5650 (Westmere-EP, 6 cores, 2.67GHz) processors
- 12 cores/node & 48 gigabytes of memory/node
- GPU Node:
- 128 NVIDIA Tesla M2070 GPUs
- 873 GB of local disk space in '/tmp'
- QDR IB Interconnect (40Gbps)
- Low latency
- High throughput
- High quality-of-service.
- Theoretical system peak performance
- 88.6 teraflops
- GPU acceleration
- Additional 65.5 teraflops
- Total peak performance
- 154.1 teraflops
- Memory Increase
- Increases memory from 2.5 gigabytes per core of Glenn system to 4.0 gigabytes per core.
- System Efficiency
- 1.5x the performance of former Glenn system at just 60 percent of current power consumption.
How to Connect
-
SSH Method
To login to Oakley at OSC, ssh to the following hostname:
oakley.osc.edu
You can either use an ssh client application or execute ssh on the command line in a terminal window as follows:
ssh <username>@oakley.osc.edu
You may see warning message including SSH key fingerprint. Verify that the fingerprint in the message matches one of the SSH key fingerprint listed here, then type yes.
From there, you are connected to Oakley login node and have access to the compilers and other software development tools. You can run programs interactively or through batch requests. We use control groups on login nodes to keep the login nodes stable. Please use batch jobs for any compute-intensive or memory-intensive work. See the following sections for details.
-
OnDemand Method
You can also login to Oakley at OSC with our OnDemand tool. The first is step is to login to OnDemand. Then once logged in you can access Ruby by clicking on "Clusters", and then selecting ">_Oakley Shell Access".
Instructions on how to connect to OnDemand can be found at the OnDemand documentation page.
Batch Specifics
qsub to provide more information to clients about the job they just submitted, including both informational (NOTE) and ERROR messages. To better understand these messages, please visit the messages from qsub page.Refer to the documentation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- Compute nodes on Oakley are 12 cores/processors per node (ppn). Parallel jobs must use
ppn=12. -
If you need more than 48 GB of RAM per node, you may run on the 8 large memory (192 GB) nodes on Oakley ("bigmem"). You can request a large memory node on Oakley by using the following directive in your batch script:
nodes=XX:ppn=12:bigmem, where XX can be 1-8. - We have a single huge memory node ("hugemem"), with 1 TB of RAM and 32 cores. You can schedule this node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=32. This node is only for serial jobs, and can only have one job running on it at a time, so you must request the entire node to be scheduled on it. In addition, there is a walltime limit of 48 hours for jobs on this node.
nodes=1:ppn=32 with a walltime of 48 hours or less, and the scheduler will put you on the 1 TB node.- GPU jobs may request any number of cores and either 1 or 2 GPUs. Request 2 GPUs per a node by adding the following directive to your batch script:
#PBS -l nodes=1:ppn=12:gpus=2
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Technical Specifications
The following are technical specifications for Oakley. We hope these may be of use to the advanced user.
| Oakley System (2012) | |
|---|---|
| Number oF nodes | 670 nodes |
| Number of CPU Cores | 8,328 (12 cores/node) |
| Cores per Node | 12 cores/node |
| Local Disk Space per Node | ~810GB in /tmp, SATA |
| Compute CPU Specifications |
Intel Xeon x5650 (Westmere-EP) CPUs
|
| Computer Server Specifications |
HP SL390 G7 |
|
Accelerator Specifications |
NVIDIA Tesla M2070 |
| Number of accelerator Nodes |
128 GPUs |
| Memory Per Node |
48GB |
| Memory Per Core | 4GB |
| Interconnect |
QDR IB Interconnect
|
| Login Specifications |
2 Intel Xeon x5650
|
| Special Nodes |
Large Memory (8)
Huge Memory (1)
|
Batch Limit Rules
Memory Limit:
It is strongly suggested to consider the memory use to the available per-core memory when users request OSC resources for their jobs. On Oakley, it equates to 4GB/core and 48GB/node.
If your job requests less than a full node ( ppn< 12), it may be scheduled on a node with other running jobs. In this case, your job is entitled to a memory allocation proportional to the number of cores requested (4GB/core). For example, without any memory request ( mem=XX ), a job that requests nodes=1:ppn=1 will be assigned one core and should use no more than 4GB of RAM, a job that requests nodes=1:ppn=3 will be assigned 3 cores and should use no more than 12GB of RAM, and a job that requests nodes=1:ppn=12 will be assigned the whole node (12 cores) with 48GB of RAM. However, a job that requests nodes=1:ppn=1,mem=12GB will be assigned one core but have access to 12GB of RAM, and charged for 3 cores worth of Resource Units (RU). See Charging for memory use for more details.
A multi-node job ( nodes>1 ) will be assigned the entire nodes with 48GB/node and charged for the entire nodes regardless of ppn request. For example, a job that requests nodes=10:ppn=1 will be charged for 10 whole nodes (12 cores/node*10 nodes, which is 120 cores worth of RU). A job that requests large-memory node ( nodes=XX:ppn=12:bigmem, XX can be 1-8) will be allocated the entire large-memory node with 192GB of RAM and charged for the whole node (12 cores worth of RU). A job that requests huge-memory node ( nodes=1:ppn=32 ) will be allocated the entire huge-memory node with 1TB of RAM and charged for the whole node (32 cores worth of RU).
To manage and monitor your memory usage, please refer to Out-of-Memory (OOM) or Excessive Memory Usage.
GPU Limit:
On Oakley, GPU jobs may request any number of cores and either 1 or 2 GPUs ( nodes=XX:ppn=XX: gpus=1 or gpus=2 ). The memory limit depends on the ppn request and follows the rules in Memory Limit.
Walltime Limit
Here are the queues available on Oakley:
|
NAME |
MAX WALLTIME |
MAX JOB SIZE |
NOTES |
|---|---|---|---|
|
Serial |
168 hours |
1 node |
|
|
Longserial |
336 hours |
1 node |
Restricted access |
|
Parallel |
96 hours |
125 nodes |
|
|
Longparallel |
250 hours |
230 nodes |
Restricted access |
|
Hugemem |
48 hours |
1 node |
32 core with 1 TB RAM
|
|
Debug |
1 hour |
12 nodes |
|
Job Limit
An individual user can have up to 256 concurrently running jobs and/or up to 2040 processors/cores in use. All the users in a particular group/project can among them have up to 384 concurrently running jobs and/or up to 2040 processors/cores in use. Jobs submitted in excess of these limits are queued but blocked by the scheduler until other jobs exit and free up resources.
A user may have no more than 1000 jobs submitted to both the parallel and serial job queue separately. Jobs submitted in excess of this limit will be rejected.
Citation
For more information about citations of OSC, visit https://www.osc.edu/citation.
To cite Oakley, please use the following Archival Resource Key:
ark:/19495/hpc0cvqn
Please adjust this citation to fit the citation style guidelines required.
Ohio Supercomputer Center. 2012. Oakley Supercomputer. Columbus, OH: Ohio Supercomputer Center. http://osc.edu/ark:19495/hpc0cvqn
Here is the citation in BibTeX format:
@misc{Oakley2012,
ark = {ark:/19495/hpc0cvqn},
howpublished = {\url{http://osc.edu/ark:/19495/hpc0cvqn}},
year = {2012},
author = {Ohio Supercomputer Center},
title = {Oakley Supercomputer}
}
And in EndNote format:
%0 Generic %T Oakley Supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc0cvqn %U http://osc.edu/ark:/19495/hpc0cvqn %D 2012
Here is an .ris file to better suit your needs. Please change the import option to .ris.
Oakley SSH key fingerprints
These are the public key fingerprints for Oakley:
oakley: ssh_host_key.pub = 01:21:16:c4:cd:43:d3:87:6d:fe:da:d1:ab:20:ba:4a
oakley: ssh_host_rsa_key.pub = eb:83:d9:ca:88:ba:e1:70:c9:a2:12:4b:61:ce:02:72
oakley: ssh_host_dsa_key.pub = ef:4c:f6:cd:83:88:d1:ad:13:50:f2:af:90:33:e9:70
These are the SHA256 hashes:
oakley: ssh_host_key.pub = SHA256:685FBToLX5PCXfUoCkDrxosNg7w6L08lDTVsjLiyLQU
oakley: ssh_host_rsa_key.pub = SHA256:D7HjrL4rsYDGagmihFRqy284kAcscqhthYdzT4w0aUo
oakley: ssh_host_dsa_key.pub = SHA256:XplFCsSu7+RDFC6V/1DGt+XXfBjDLk78DNP0crf341U
Queues and Reservations
Here are the queues available on Oakley. Please note that you will be routed to the appropriate queue based on your walltime and job size request.
| Name | Nodes available | max walltime | max job size | notes |
|---|---|---|---|---|
|
Serial |
Available minus reservations |
168 hours |
1 node |
|
|
Longserial |
Available minus reservations |
336 hours |
1 node |
Restricted access |
|
Parallel |
Available minus reservations |
96 hours |
125 nodes |
|
|
Longparallel |
Available minus reservations |
250 hours |
230 nodes |
Restricted access |
|
Hugemem |
1 |
48 hours |
1 node |
"Available minus reservations" means all nodes in the cluster currently operational (this will fluctuate slightly), less the reservations listed below. To access one of the restricted queues, please contact OSC Help. Generally, access will only be granted to these queues if the performance of the job cannot be improved, and job size cannot be reduced by splitting or checkpointing the job.
In addition, there are a few standing reservations.
| Name | Nodes Available | Max Walltime | Max job size | notes |
|---|---|---|---|---|
| Debug |
12 regualr nodes 4 GPU nodes |
1 hour | 16 nodes | For small interactive and test jobs during 8AM-6PM, Monday - Friday. |
| GPU | 62 | 336 hours | 62 nodes |
Small jobs not requiring GPUs from the serial and parallel queues will backfill on this reservation. |
| OneTB | 1 | 48 hours | 1 node | Holds the 32 core, 1 TB RAM node aside for the hugemem queue. |
Occasionally, reservations will be created for specific projects that will not be reflected in these tables.
AMD Linux cluster (MPP)
 OSC engineers in March, 2002, installed a 256-CPU AMD Linux Cluster. The 32-bit Parallel Processing (MPP) system featured one gigabyte of distributed memory, 256 1.4 & 1.53 gigahertz AMD Athlon processors and a Myrinet and Fast Ethernet interconnect.
OSC engineers in March, 2002, installed a 256-CPU AMD Linux Cluster. The 32-bit Parallel Processing (MPP) system featured one gigabyte of distributed memory, 256 1.4 & 1.53 gigahertz AMD Athlon processors and a Myrinet and Fast Ethernet interconnect.
Apple Xserve G5 Cluster
 next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.
next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.BALE cluster
 In July, 2002, OSC officials put the finishing touches on a $1.5 million, 7,040-square-foot expansion called the Blueprint for Advanced Learning Environment, or BALE. OSC deployed more than 50 NVIDIA Quadro™4 900 XGL workstation graphics boards to power the BALE Cluster for volume rendering of graphics applications.
In July, 2002, OSC officials put the finishing touches on a $1.5 million, 7,040-square-foot expansion called the Blueprint for Advanced Learning Environment, or BALE. OSC deployed more than 50 NVIDIA Quadro™4 900 XGL workstation graphics boards to power the BALE Cluster for volume rendering of graphics applications.
BALE provided an environment for testing and validating the effectiveness of new tools, technologies and systems in a workplace setting, including a theater, conference space and the OSC Interface Lab. BALE Theater featured about 40 computer workstations powered by a visualization cluster. When workstations were not being used in the Theatre, the cluster was used for parallel computation and large scientific data visualization.
Near the end of January 2007, OSC upgraded its BALE Cluster, a distributed/shared memory hybrid system constructed from commodity PC components running the Linux OS. The more powerful system resided in a separate server room from OSC’s on-site training facility, eliminating classroom noise and heat generated from the computers. This improved environment allowed students to run hands-on exercises faster without distractions. The updated cluster boasted 55 rack-mounted compute nodes. Each node contained a dual core AMD Athlon 64 processor integrated with nVIDIA GeForce 6150 graphics processing units (GPU). An application taking full advantage of the system, using all AMD and nVIDIA processing units, could reach one trillion calculations per second.
Beowulf
In April, 1999, OSC installed a 10-CPU IA32 Linux Cluster as a “Beowulf Cluster,” a system built of commodity off-the-shelf (COTS) components dedicated for parallel use and running an open source operating system and tool set. OSC developed this cluster to create an experimental test bed for testing new parallel algorithms and commodity communications hardware, to design a model system for cluster systems to be set up by members of the OSC user community and to establish a high performance parallel computer system in its own right.
Brain
 Later in 1999, OSC purchased a cluster of 33 SGI 1400L systems (running Linux). These systems were connected with Myricom's Myrinet high-speed network and used as a “Beowulf cluster on steroids.” This cluster, nicknamed the Brain (after Pinky's smarter half on Animaniacs), was initially assembled and tested in one of SGI's HPC systems labs in Mountain View, Calif., in October. It was then shipped to Portland, Ore., where it was featured and demoed prominently in SGI's booth at the Supercomputing '99 conference. After SC99, the cluster was dismantled and shipped to OSC’s offices, where it was permanently installed.
Later in 1999, OSC purchased a cluster of 33 SGI 1400L systems (running Linux). These systems were connected with Myricom's Myrinet high-speed network and used as a “Beowulf cluster on steroids.” This cluster, nicknamed the Brain (after Pinky's smarter half on Animaniacs), was initially assembled and tested in one of SGI's HPC systems labs in Mountain View, Calif., in October. It was then shipped to Portland, Ore., where it was featured and demoed prominently in SGI's booth at the Supercomputing '99 conference. After SC99, the cluster was dismantled and shipped to OSC’s offices, where it was permanently installed.
CRAY T3E
 In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T3E-600/LC housed 136 Alpha EV5 processors at 300MHz and 16GB of memory.
In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T3E-600/LC housed 136 Alpha EV5 processors at 300MHz and 16GB of memory.
CRAY T94
 In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T94 featured four custom vector processors at 450MHz and 1GB of memory.
In November, 1997, OSC also installed two additional HPC systems, a CRAY T94 and a CRAY T3E. These systems replaced a CRAY Y-MP and a CRAY T3D, two of the Center’s most utilized systems. The T94 featured four custom vector processors at 450MHz and 1GB of memory.
Convex Exemplar SPP1220
 OSC engineers in 1995 installed a Convex Exemplar SPP1220 system, a recently upgraded version of Convex’s popular SPP1000 system, featuring a new processor, memory and I/O package.
OSC engineers in 1995 installed a Convex Exemplar SPP1220 system, a recently upgraded version of Convex’s popular SPP1000 system, featuring a new processor, memory and I/O package.
Cray J90se
 In June, 1997, OSC engineers installed the Cray J90se system. This Scalar Enhanced series doubled the scalar speed of the processors on the base J90 model to 200 MHz; the vector chip remained at 100 MHz.
In June, 1997, OSC engineers installed the Cray J90se system. This Scalar Enhanced series doubled the scalar speed of the processors on the base J90 model to 200 MHz; the vector chip remained at 100 MHz.
Cray SV1
 In October, 1999, OSC engineers installed a Cray SV1 system with 16 custom vector processors at 300MHz and 16GB of memory. The SV1 used complementary metal–oxide–semiconductor (CMOS) processors, which lowered the cost of the system, and allowed the computer to be air-cooled.
In October, 1999, OSC engineers installed a Cray SV1 system with 16 custom vector processors at 300MHz and 16GB of memory. The SV1 used complementary metal–oxide–semiconductor (CMOS) processors, which lowered the cost of the system, and allowed the computer to be air-cooled.
In 2004, OSC announced an upgrade to its SV-1ex vector supercomputer that increased its processing capacity by 33 percent. With the addition of eight new processors, peak performance was then 64 Gigaflops, delivering the computing power of roughly 64 billion calculators all yielding an answer each and every second. Originally purchased in 1999, the SV1ex upgrade significantly increases the performance capacity of a system that had proven to be a workhorse for the research community.
Cray T3D MPP
 On April 18, 1994, OSC engineers took delivery of a 32-processor Cray T3D MPP, an entry-level massively parallel processing system. Each of the processors included a DEC Alpha chip, eight megawords of memory and Cray-designed memory logic.
On April 18, 1994, OSC engineers took delivery of a 32-processor Cray T3D MPP, an entry-level massively parallel processing system. Each of the processors included a DEC Alpha chip, eight megawords of memory and Cray-designed memory logic.
Cray X-MP/24
 Ohio State in the spring of 1987 budgeted $8.2 million over the next five years to lease a Cray X-MP/24, OSP’s first real supercomputer. The X-MP arrived June 1 at the OSU IRCC loading dock on Kinnear Road.
Ohio State in the spring of 1987 budgeted $8.2 million over the next five years to lease a Cray X-MP/24, OSP’s first real supercomputer. The X-MP arrived June 1 at the OSU IRCC loading dock on Kinnear Road.
Cray X1
 The OSC-Springfield offices would officially open in April 2004. Over the next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.
The OSC-Springfield offices would officially open in April 2004. Over the next several months, OSC engineers would install the 16-MSP Cray X1 system, the Cray XD1 system and the 33-node Apple Xserve G5 Cluster at Springfield office. A 1-Gbit/s Ethernet WAN service linked the cluster to OSC’s remote-site hosts in Columbus. The G5 Cluster featured one front-end node configured with four gigabytes of RAM, two 2.0 gigahertz PowerPC G5 processors, 2-Gigabit Fibre Channel interfaces, approximately 750 gigabytes of local disk and about 12 terabytes of Fibre Channel attached storage.Cray XD1
Cray Y-MP 2E
 In 1994 OSC installed a Cray Y-MP 2E as a complement machine to the Cray T3D MPP.
In 1994 OSC installed a Cray Y-MP 2E as a complement machine to the Cray T3D MPP.
Cray Y-MP8/864
 In August 1989, OSC engineers completed the installation of the $22 million Cray Y-MP8/864 system, which was deemed the largest and fastest supercomputer in the world for a short time. The seven-ton system was able to calculate 200 times faster than many mainframes at that time and underwent several weeks of stress testing from “friendly users, who loaded the machine to 97 percent capacity for 17 consecutive days.
In August 1989, OSC engineers completed the installation of the $22 million Cray Y-MP8/864 system, which was deemed the largest and fastest supercomputer in the world for a short time. The seven-ton system was able to calculate 200 times faster than many mainframes at that time and underwent several weeks of stress testing from “friendly users, who loaded the machine to 97 percent capacity for 17 consecutive days.
“The lightning speed of the supercomputer allows scientists to work massive problems in real-time, without having to wait days or weeks for the results of larger computer runs,” according to a Sept. 28, 1989, article in Ohio State’s faculty and staff newsletter, OnCampus. “The CRAY Y-MP8/864 performs 2.7 billion calculations per second.”
Glenn

The Ohio Supercomputer Center's IBM Cluster 1350, named "Glenn", features AMD Opteron multi-core technologies. The system offers a peak performance of more than 54 trillion floating point operations per second and a variety of memory and processor configurations. The current Glenn Phase II components were installed and deployed in 2009, while the earlier phase of Glenn – now decommissioned – had been installed and deployed in 2007.
 03/24/2016: Glenn Cluster has been retired. Please see our FAQ page.
03/24/2016: Glenn Cluster has been retired. Please see our FAQ page.Hardware
The hardware configuration consisted of the following:
- 436 System x3455 compute nodes
- Dual socket, quad core 2.5 GHz Opterons
- 24 GB RAM
- 393 GB local disk space in /tmp
- 2 System x3755 login nodes
- Quad socket quad core 2.4 GHz Opterons
- 64 GB RAM
- Voltaire 20 Gbps PCI Express adapters
There were 36 GPU-capable nodes on Glenn, connected to 18 Quadro Plex S4's for a total of 72 CUDA-enabled graphics devices. Each node had access to two Quadro FX 5800-level graphics cards.
- Each Quadro Plex S4 had these specs:
- Each Quadro Plex S4 contains 4 Quadro FX 5800 GPUs
- 240 cores per GPU
- 4GB Memory per card
- The 36 compute nodes in Glenn contained:
- Dual socket, quad core 2.5 GHz Opterons
- 24 GB RAM
- 393 GB local disk space in '/tmp'
- 20Gb/s Infiniband ConnectX host channel adapater (HCA)
How to Connect
To connect to Glenn, ssh to glenn.osc.edu.
Batch Specifics
Refer to the documenation for our batch environment to understand how to use PBS on OSC hardware. Some specifics you will need to know to create well-formed batch scripts:
- All compute nodes on Glenn are 8 cores/processors per node (ppn). Parallel jobs must use
ppn=8. - If you need more than 24 GB of RAM per node, you will need to run your job on Oakley.
- GPU jobs must request whole nodes (ppn=8) and are allocated two GPUs each.
Using OSC Resources
For more information about how to use OSC resources, please see our guide on batch processing at OSC. For specific information about modules and file storage, please see the Batch Execution Environment page.
Batch Limit Rules
Memory Limit:
It is strongly suggested to consider the memory use to the available per-core memory when users request OSC resources for their jobs. On Glenn, it equates to 3GB/core and 24GB/node.
If your job requests less than a full node ( ppn<8 ), it may be scheduled on a node with other running jobs. In this case, your job is entitled to a memory allocation proportional to the number of cores requested (3GB/ core). For example, without any memory request ( mem=XX ), a job that requests nodes=1:ppn=1 will be assigned one core and should use no more than 3GB of RAM, a job that requests nodes=1:ppn=3 will be assigned 3 cores and should use no more than 9GB of RAM, and a job that requests nodes=1:ppn=8 will be assigned the whole node (8 cores) with 24GB of RAM. It is important to keep in mind that the memory limit ( mem=XX ) you set in PBS does not work the way one might expect it to on Glenn. It does not cause your job to be allocated the requested amount of memory, nor does it limit your job’s memory usage. For example, a job that requests nodes=1:ppn=1,mem=9GB will be assigned one core (which means you should use no more than 3GB of RAM instead of the requested 9GB of RAM) and you were only charged for one core worth of Resource Units (RU).
A multi-node job ( nodes>1 ) will be assigned the entire nodes with 24GB/node. Jobs requesting more than 24GB/node should be submitted to other clusters (Oakley or Ruby)
To manage and monitor your memory usage, please refer to Out-of-Memory (OOM) or Excessive Memory Usage.
Walltime Limit
Here are the queues available on Glenn:
|
NAME |
MAX WALLTIME |
NOTES |
|---|---|---|
|
Serial |
168 hours |
|
|
Longserial |
336 hours |
Restricted access |
|
Parallel |
96 hours |
|
Job Limit
An individual user can have up to 128 concurrently running jobs and/or up to 2048 processors/cores in use. All the users in a particular group/project can among them have up to 192 concurrently running jobs and/or up to 2048 processors/cores in use. Jobs submitted in excess of these limits are queued but blocked by the scheduler until other jobs exit and free up resources.
A user may have no more than 1,000 jobs submitted to a queue; parallel and serial job queues are treated separately. Jobs submitted in excess of these limits will be rejected.
Citation
Glenn retired from service on March 24, 2016.
To cite Glenn, please use the following Archival Resource Key:
ark:/19495/hpc1ph70
Here is the citation in BibTeX format:
@article{Glenn2009,
ark = {ark:/19495/hpc1ph70},
url = {http://osc.edu/ark:/19495/hpc1ph70},
year = {2009},
author = {Ohio Supercomputer Center},
title = {Glenn supercomputer}
}
And in EndNote format:
%0 Generic %T Glenn supercomputer %A Ohio Supercomputer Center %R ark:/19495/hpc1ph70 %U http://osc.edu/ark:/19495/hpc1ph70 %D 2009
Here is an .ris file to better suit your needs. Please change the import option to .ris.
Glenn Retirement
Glenn Cluster Retired: March 24, 2016
The Glenn Cluster supercomputer has been retired from service to make way for a much more powerful new system. As an OSC client, the removal of the cluster will result in work being added to the heavy workload being handled by Oakley or Ruby, potentially impacting you.
Why is Glenn being retired?
Glenn is our oldest and least efficient cluster. In order to make room for our new cluster, to be installed later in 2016, we must remove Glenn to prepare the space and do some facilities work.
How will this impact me?
Demand for computing services is already high, and removing approximately 20 percent of our total FLOP capability will likely result in more time spent waiting in the queue. Please be patient with the time it takes for your jobs to run. We will be monitoring the queues, and may make scheduler adjustments to achieve better efficiency.
How long will it take before the new cluster is online?
We expect the new cluster to be partially deployed by Aug. 1, and completely deployed by Oct. 1. Even in the partially deployed state, there will be more available nodes: 1.5x more cores, and roughly 3x more FLOPs available than there are today.
Is there more information on the new cluster?
Please see our webpage: https://www.osc.edu/supercomputing/computing/c16.
Need help, or have further questions?
We will help. Please let us know if you have any paper deadlines or similar requirements. We may be able to make some adjustments to make your work more efficient, or to help it get through the queue more quickly. To see what things you should consider if you have work to migrate off of Glenn, please visit https://www.osc.edu/glennretirement.
Please contact OSC Help, our 24/7 help desk.
Toll Free: (800) 686-6472
Local: (614) 292-1800
Email: oschelp@osc.edu
Queues and Reservations
Here are the queues available on Glenn. Please note that you will be routed to the appropriate queue based on your walltime and job size request.
| Name | Nodes available | max walltime | max job size | notes |
|---|---|---|---|---|
|
Serial |
Available minus reservations |
168 hours |
1 node |
|
|
Longserial |
Available minus reservations |
336 hours |
1 node |
Restricted access |
|
Parallel |
Available minus reservations |
96 hours |
256 nodes |
|
|
Dedicated |
Entire cluster |
48 hours |
436 nodes |
Restricted access |
"Available minus reservations" means all nodes in the cluster currently operational (this will fluctuate slightly), less the reservations listed below. To access one of the restricted queues, please contact OSC Help. Generally, access will only be granted to these queues if performance of the job cannot be improved, and job size cannot be reduced by splitting or checkpointing the job.
In addition, there are a few standing reservations.
| Name | Times | Nodes Available | Max Walltime | Max job size | notes |
|---|---|---|---|---|---|
| Debug | 8AM-6PM Weekdays | 16 | 1 hour | 16 nodes | For small interactive and test jobs. |
| GPU | ALL | 32 | 336 hours | 32 nodes |
Small jobs not requiring GPUs from the serial and parallel queues will backfill on this reservation. |
Occasionally, reservations will be created for specific projects that will not be reflected in these tables.
Glenn Phase I
In June, 2007, OSC purchased a 4212-CPU IBM Opteron Cluster (Phase 1) and named the cluster after former astronaut and statesman John Glenn. The acquisition of the IBM Cluster 1350 included the latest AMD Opteron multi-core technologies and the new IBM cell processors. Ten times as powerful as any of OSC’s current systems, the system offered a peak performance of more than 22 trillion floating point operations per second. OSC’s new supercomputer also included blade systems based on the Cell Broadband Engine processor. This allowed Ohio researchers and industries to easily use this new hybrid HPC architecture.
IBM RISC System/6000* Scalable POWERparallel Systems * SP2
 In April, 1995, OSC engineers began installing a powerful new computer at the OSC/KRC – an IBM RISC System/6000* Scalable POWERparallel Systems * SP2. The SP2 could run several numeric-intensive and data-intensive projects across different processors – which allowed different users across the state to use the SP2 at the same time – or handle a single project quickly by distributing the calculations equally across its available processors.
In April, 1995, OSC engineers began installing a powerful new computer at the OSC/KRC – an IBM RISC System/6000* Scalable POWERparallel Systems * SP2. The SP2 could run several numeric-intensive and data-intensive projects across different processors – which allowed different users across the state to use the SP2 at the same time – or handle a single project quickly by distributing the calculations equally across its available processors.
"We selected the SP2 largely because of its ability to use a high-speed switch to interconnect the processors, and the assignment of disk units to individual nodes in order to optimize parallel I/O," said Al Stutz, OSC's associate director.
Itanium 2 cluster
In October, 2002, OSC engineers installed the 300-CPU HP Workstation Itanium 2 Linux zx6000 Cluster. OSC selected HP’s computing cluster for its blend of high performance, flexibility and low cost. The HP cluster used Myricom's Myrinet high-speed interconnect and ran the Red Hat Linux Advanced Workstation, a 64-bit Linux operating system.
Lego
 OSC engineers were busy again in September of 1998, installing an SGI Origin 2000 system at the Center. The SGI Origin 2000, code named Lego, came from a family of mid-range and high-end servers developed and manufactured by Silicon Graphics Inc. (SGI) to succeed the SGI Challenge and POWER Challenge. The SGI Origin 2000 contained 32 MIPS R12000 processors at 300MHz and 16GB of memory.
OSC engineers were busy again in September of 1998, installing an SGI Origin 2000 system at the Center. The SGI Origin 2000, code named Lego, came from a family of mid-range and high-end servers developed and manufactured by Silicon Graphics Inc. (SGI) to succeed the SGI Challenge and POWER Challenge. The SGI Origin 2000 contained 32 MIPS R12000 processors at 300MHz and 16GB of memory.
PIV cluster
 In December, 2003, OSC engineers installed a 512-CPU Pentium 4 Linux Cluster. Replacing the AMD Athlon cluster, the P4 doubled the existing system’s power with a sizable increase in speed. With a theoretical peak of 2,457 gigaflops, the P4 cluster contained 256 dual-processor Pentium IV Xeon systems with four gigabytes of memory per node and 20 terabytes of aggregate disk space. It was connected via a gigabit Ethernet and used Voltair InfiniBand 4x HCA, and a Voltair ISR 9600 InfiniBand switch router for high-speed interconnect.
In December, 2003, OSC engineers installed a 512-CPU Pentium 4 Linux Cluster. Replacing the AMD Athlon cluster, the P4 doubled the existing system’s power with a sizable increase in speed. With a theoretical peak of 2,457 gigaflops, the P4 cluster contained 256 dual-processor Pentium IV Xeon systems with four gigabytes of memory per node and 20 terabytes of aggregate disk space. It was connected via a gigabit Ethernet and used Voltair InfiniBand 4x HCA, and a Voltair ISR 9600 InfiniBand switch router for high-speed interconnect.
Pinky
Early in 1999, Pinky, a small cluster of five dual-processor Pentium II systems connected with Myrinet, was made available to OSC users on a limited basis. Pinky was named for a good-natured but feebleminded lab mouse in the animated television series Animaniacs.
SGI 750 Itanium Cluster
 In August, 2001, OSC engineers installed a 146-CPU SGI 750 Itanium Linux Cluster, described by SGI as one of the fastest in the world. The system – with 292GB memory, 428GFLOPS peak performance for double-precision computations and 856GFLOPS peak performance for single-precision computations – followed the Pentium® III Xeon™ cluster that had been operated at OSC for the preceding 18 months. This system was the first Itanium processor-based cluster installed by SGI.
In August, 2001, OSC engineers installed a 146-CPU SGI 750 Itanium Linux Cluster, described by SGI as one of the fastest in the world. The system – with 292GB memory, 428GFLOPS peak performance for double-precision computations and 856GFLOPS peak performance for single-precision computations – followed the Pentium® III Xeon™ cluster that had been operated at OSC for the preceding 18 months. This system was the first Itanium processor-based cluster installed by SGI.
SGI Altix 350
SGI Altix 3700
 In September, 2003, OSC engineers installed a SGI Altix 3700 system to replace its SGI Origin 2000 system and to augment its HP Itanium 2 Cluster. The Altix was a non-uniform memory access system with 32 Itanium processors and 64 gigabytes of memory. The Altix featured Itanium 2 processors and runs the Linux operating system. OSC's HP Cluster also included Itanium 2 processors and runs Linux. The cluster and Altix were distinguished by the way memory is accessed and its availability to any or all processors.
In September, 2003, OSC engineers installed a SGI Altix 3700 system to replace its SGI Origin 2000 system and to augment its HP Itanium 2 Cluster. The Altix was a non-uniform memory access system with 32 Itanium processors and 64 gigabytes of memory. The Altix featured Itanium 2 processors and runs the Linux operating system. OSC's HP Cluster also included Itanium 2 processors and runs Linux. The cluster and Altix were distinguished by the way memory is accessed and its availability to any or all processors.
SGI Power Challenge system
In October, 1995 OSC engineers installed an SGI Power Challenge system at the KRC site. The SGI system featured 16 processors, two gigabytes of main memory (8-way interleaved), and four megabytes of secondary cache.
SunFire 6800
 In October, 2001, OSC engineers installed four SunFire 6800 midframe servers, with a total of 72 UltraSPARC III processors.
In October, 2001, OSC engineers installed four SunFire 6800 midframe servers, with a total of 72 UltraSPARC III processors.